MySQL
基本架构
连接器->分析器->优化器->执行器->存储引擎
更新语句的执行流程
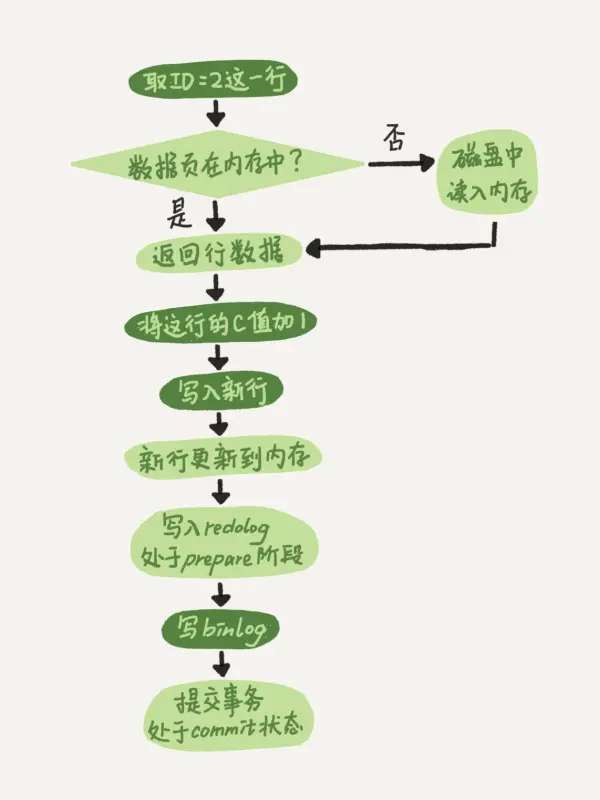
为什么需要两段提交
由于 redo log 和 binlog 是两个独立的逻辑,如果不用两阶段提交,要么就是先写完 redo log 再写 binlog,或者采用反过来的顺序。我们看看这两种方式会有什么问题。
仍然用前面的 update 语句来做例子。假设当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了 crash,会出现什么情况呢?
- 先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。
但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。
然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。 - 先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
事务的隔离级别
| 隔离级别 | 描述 |
|---|---|
| 读未提交 | 事务可以读取未提交的数据 |
| 读已提交 | 事务只能读取已提交的数据 |
| 可重复读 | 事务在开始时看到的数据一致 |
| 串行化 | 事务完全隔离,避免并发冲突 |
参数
| 用途 | 命令 |
|---|---|
| 查看事务隔离级别 | show variables like 'transaction_isolation'; |
为什么 MySQL 索引使用 B+树?
- 减少 I/O 次数: B+树的非叶子节点只存储索引,不存储数据,可以容纳更多的索引,减少树的高度,从而减少 I/O 次数。
- 范围查询效率高: B+树的叶子节点通过指针连接成有序链表,可以方便地进行范围查询。
- 磁盘友好: B+树的节点大小通常设置为磁盘页大小,可以一次性加载一个节点到内存,减少磁盘 I/O 次数。
索引
- 主键索引: Mysql 会为建立一个主键的索引树,这棵索引树包含了整行的数据
- 普通索引: 普通索引存储的是主键 ID
- 覆盖索引: 查询的字段已经在索引里包含了,无需回表
- 索引下推: 索引里包含的字段值可以在查询的时候直接过滤,减少了回表次数。
为什么应该选择普通索引,而不是唯一索引。
这两者在查询的时候没有区别,但在插入的时候,由于唯一索引需要检查这个值是否存在,就需要从表里把数据加载进来,
这就涉及到磁盘 IO,磁盘 IO 是很慢的,所以唯一索引在插入的时候就明显慢于普通索引。
结合以上两点,应该优先选择普通索引,可考虑在程序中保证唯一性。
索引失效的情况
- 在索引列使用了函数计算
- 隐式类型转换,也就是索引字段类型和查询值类型不匹配
- 不符合最左前缀原则
- 使用 like 且通配符在前面
- 两个表的连接列需要索引
死锁检测
1 | [mysqld] |
将全部死锁信息记录到日志中
死锁优化:
- 确保事务尽可能小而快,减少锁持有时间
- 保证所有事务以相同的顺序访问表
- 为大事务考虑拆分多个小事务
- 优化查询索引,确保事务使用合适的索引
InnoDB 刷新脏页的策略
在 MySQL 的 InnoDB 存储引擎中,为了提高读写效率,数据和索引首先被加载到 Buffer Pool 中。Buffer Pool 是内存中的一块区域,用于缓存数据和索引。当修改数据时,InnoDB 会先修改 Buffer Pool 中的数据页,这些被修改的页称为“脏页”。
什么是脏页?
脏页是指在 Buffer Pool 中被修改过,但尚未同步到磁盘的数据页。当需要读取数据时,InnoDB 会优先从 Buffer Pool 中查找,如果找到所需的页,则直接返回;否则,从磁盘加载数据页。
LRU(Least Recently Used)算法: InnoDB 使用 LRU 算法管理 Buffer Pool 中的数据页。当需要淘汰数据页时,优先淘汰最近最少使用的页。如果最近最少使用的页是脏页,则需要先将其刷新到磁盘。
后台线程定期刷新: InnoDB 后台有一个专门的线程负责定期将脏页刷新到磁盘。
Redo log 写满: 当 Redo log 写满时,InnoDB 会强制将一部分脏页刷新到磁盘,以腾出空间写入新的 Redo log。
内存不足: 当系统内存不足时,操作系统会通知 InnoDB,InnoDB 会将一部分脏页刷新到磁盘,以释放内存。
正常关闭数据库: 在正常关闭数据库时,InnoDB 会将所有脏页刷新到磁盘,以保证数据的一致性。
一旦一个查询请求需要在执行过程中先 flush 掉一个脏页时,这个查询就可能要比平时慢.
为什么删除表数据,表文件大小不变
如果我们用 delete 命令把整个表的数据删除,所有的数据页都会被标记为可复用。但是磁盘上,文件不会变小。
经过大量增删改的表,都是可能是存在空洞的.
可以使用 alter table A engine=InnoDB 命令来重建表,从而达到回收表空间的目的
间隙锁
当查询条件没有使用索引,或者使用了索引但是返回多条记录的情况下,mysql 会使用间隙锁来锁住记录的间隙,来避免之间插入新的数据。
范围查询会使用间隙锁
其他
- 可使用
show processlist查看连接状态 alter table T engine=InnoDB可重建表索引,提交空间利用率SELECT * FROM information_schema.INNODB_TRX;查询当前执行的事务SHOW ENGINE INNODB STATUS;查询 INNODB 引擎的状态信息- 主动死锁检测,设置
innodb_deadlock_detect=on SELECT * FROM information_schema.INNODB_LOCKS;实时锁状态查询analyze table t命令,可以用来重新统计索引信息. 解决索引统计信息不准确导致的问题innodb_io_capacity设置成磁盘的 IOPS,来提高 InnoDB 刷新脏页的速度innodb_log_file_size: 设置 redo log 文件的大小。innodb_log_files_in_group: 设置 redo log 文件的数量。innodb_log_buffer_size: 设置 redo log buffer 的大小select * from sys.schema_table_lock_waits或者innodb_lock_waits可找出阻塞的 process_id
备忘
如果是可重复读隔离级别,事务 T 启动的时候会创建一个视图 read-view,之后事务 T 执行期间,即使有其他事务修改了数据,事务 T 看到的仍然跟在启动时看到的一样。也就是说,一个在可重复读隔离级别下执行的事务,好像与世无争,不受外界影响。
InnoDB 的数据是按数据页为单位来读写的。也就是说,当需要读一条记录的时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。在 InnoDB 中,每个数据页的大小默认是 16KB。
通常我们说 MySQL 的“双 1”配置,指的就是 sync_binlog 和 innodb_flush_log_at_trx_commit 都设置成 1。也就是说,一个事务完整提交前,需要等待两次刷盘,一次是 redo log(prepare 阶段),一次是 binlog。
sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
innodb_flush_log_at_trx_commit 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
binlog_format 应该设置成 row,而不是 statement,这样避免主从数据不一致问题,还有方便误删的时候恢复数据。
要避免大事务,会导致主从延迟。删除数据的时候应该批量小部分删除
InnoDB Buffer Pool 的大小是由参数 innodb_buffer_pool_size 确定的,一般建议设置成可用物理内存的 60%~80%。