Kafka
基本架构
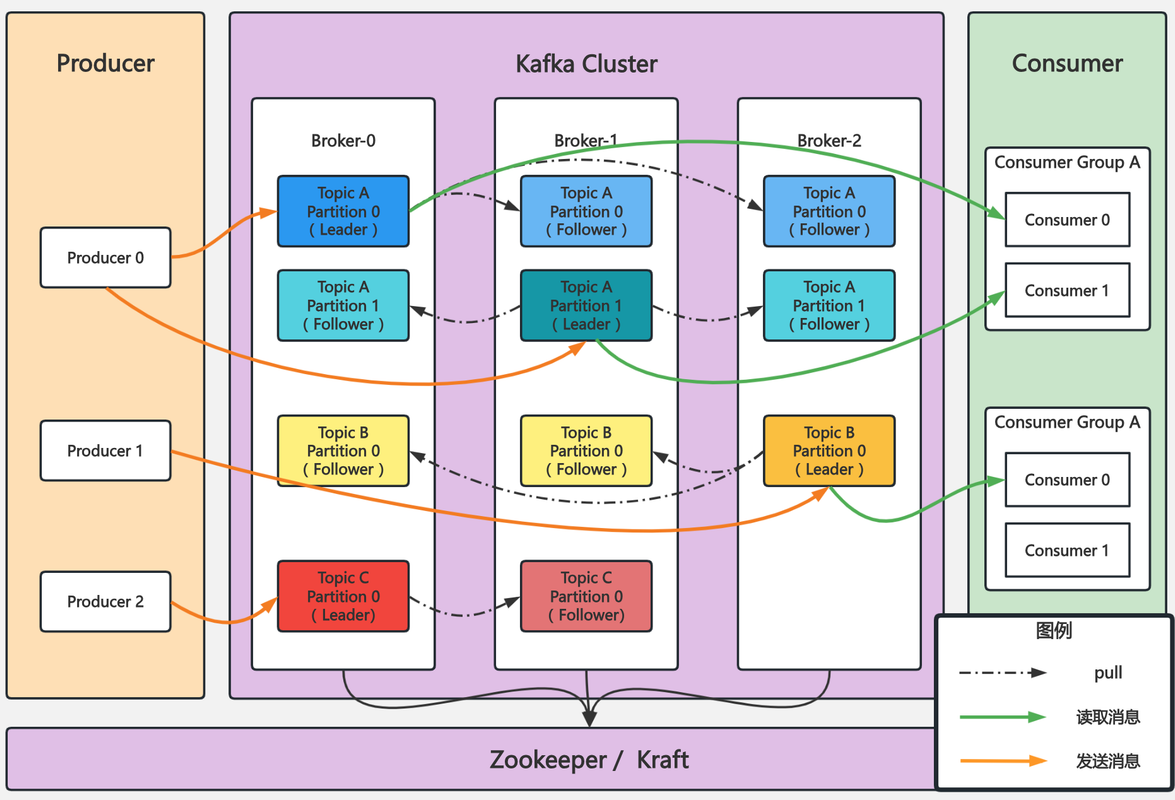
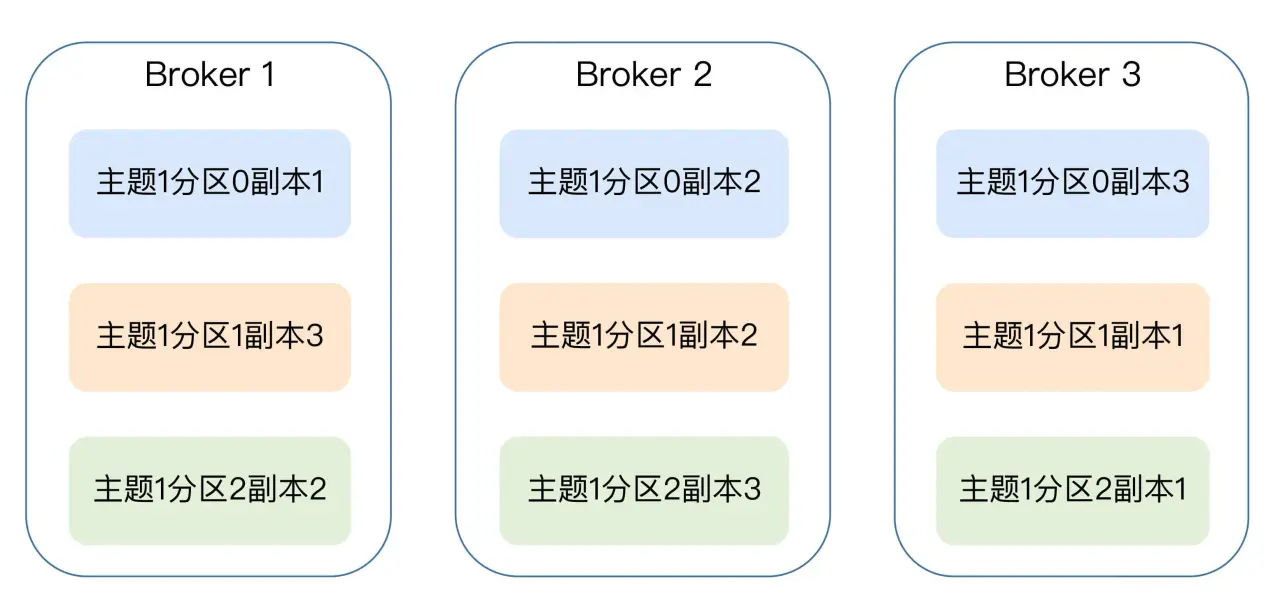
在 Kafka 中,追随者副本是不对外提供服务的。这就是说,任何一个追随者副本都不能响应消费者和生产者的读写请求。所有的请求都必须由领导者副本来处理,或者说,所有的读写请求都必须发往领导者副本所在的 Broker,由该 Broker 负责处理。追随者副本不处理客户端请求,它唯一的任务就是从领导者副本异步拉取消息,并写入到自己的提交日志中,从而实现与领导者副本的同步。
kafka 为什么这么快
- 顺序磁盘 IO
- kafka 采用追加(append-only)的日志结构,数据总是顺序写入磁盘,顺序读写速度可与内存随机访问相当。
- 零拷贝技术
- 使用 sendfile 系统调用,直接将数据从 page cache 传输到网卡,避免内核态与用户态的数据拷贝
- 批量处理
- Producer:批量发送消息
- Broker:批量持久化/压缩
- Consumer:批量拉取数据
- 页面缓存优化
- 使用 OS 的 page cache 缓存数据,减少真实磁盘访问次数
- 分区设计:
- 数据分配存储,支持水平扩展
- 不同分区可以并行处理
- 高效的消息格式
- 消息集批量存储
- 二进制协议带来紧凑的数据结构
参数配置
auto.create.topics.enable:是否允许自动创建 Topic。建议关闭,否则会出现莫名其妙的主题。
unclean.leader.election.enable:是否允许 Unclean Leader 选举。
auto.leader.rebalance.enable:是否允许定期进行 Leader 选举。建议设为 false,否则即使工作正常的 leader 也可能别切换。
log.retention.{hours|minutes|ms}: 设置一条消息数据保存多长时间
log.retention.bytes:这是指定 Broker 为消息保存的总磁盘容量大小。默认为-1,即 kafka 默认不限制
message.max.bytes:控制 Broker 能够接收的最大消息大小。
partitioner.class 参数:设置分区策略
设置 session.timeout.ms = 6s。即如果 Coordinator 在 6 秒之内没有收到 Group 下某 Consumer 实例的心跳,它就会认为这个 Consumer 实例已经挂了
设置 heartbeat.interval.ms = 2s。发送心跳请求频率的参数
max.poll.interval.ms: 限定了 Consumer 端应用程序两次调用 poll 方法的最大时间间隔
你要为你的业务处理逻辑留下充足的时间。这样,Consumer 就不会因为处理这些消息的时间太长而引发 Rebalance 了。
max.poll.records: 设置每次 poll 方法返回的消息数。
分区策略
- RangeAssignor (范围分区策略)
- 首先,它对每个主题的分区按照序号进行排序,然后对消费者按照字母顺序进行排序。
- 然后,它尝试将每个主题的分区均匀地分配给消费者。
- RoundRobinAssignor (轮询分区策略)
- 它将所有主题的所有分区和所有消费者都按照字母顺序排序。
- 然后,它按照轮询的方式将分区分配给消费者。
- StickyAssignor (粘性分区策略)
- 它在进行分区分配时,会尽量保持之前的分配结果不变。
- 只有在必要时(如消费者增加或减少)才会进行重新分配。
- CooperativeStickyAssignor (协作粘性分区策略)
- 与 StickyAssignor 类似,它也会尽量保持之前的分配结果不变。
- 但是,在进行重新分配时,它会采用协作的方式,逐步迁移分区,而不是一次性全部迁移
消息可靠性保障
- 最多一次(as most once): 消息可能会丢失,但不会重复发送
- 至少一次(at least once): 消息不会丢失,但有可能被重复发送
- 精确一次(exactly once): 消息不回丢失,也不会被重复发送
精确一次同通过事务和幂等性来实现
- 设置 enable.idempotence=true 时,producer 会升级成幂等性
- 设置 producer 端参数 transactional.id
- 谁知 isolation_level=read_committed,表明 consumer 只会读取事务型 producer 成功提交事务写入的消息
消费者重平衡
什么情况下会触发重平衡
1: 消费者组中增加或减少消费者
2: 分区增加或减少
3: 主题增加或减少
4: 消费者心跳超时
重平衡期间 kafka 会停止消费消息,直到重平衡完成
如何保证消息不丢失
- 生产者端使用带回调的 send 方法
- 设置 acks=1 或 all,保证至少写入一个副本
- 设置 retries,如设置 retries=3,开启重试机制,避免因网络问题而造成消息丢失。
- 设置 replication.factor >=3, broker 提供多个冗余副本
- 设置 min.insync.replicas>1, 消息至少写入一个 broker 副本
高水位和 epoch
- Epoch 确保了 Leader 副本的唯一性和版本正确性。
- 高水位确保了只有被所有副本确认的消息才能被消费者消费。
简单来说:
- Epoch 像是对 leader 版本的标识。
- 高水位像是对数据有效性的标识。
高水位:
定义:
- 高水位是一个偏移量 (offset),它表示 Kafka 分区中已经被所有副本(包括 Leader 副本和 Follower 副本)成功复制的消息的位置。
- 换句话说,高水位之前的消息,都被认为已经提交,可以被消费者安全消费。
作用:
- 消费者只能消费高水位之前的消息,高水位之后的消息对消费者不可见。
- 保证副本数据一致性: 高水位确保了只有被所有副本确认的消息才能被消费者消费,从而保证了副本之间的数据一致性。
高水位的更新:
- Leader 副本负责维护高水位。
- 当 Follower 副本成功复制 Leader 副本的消息时,会向 Leader 副本发送确认信息。
- Leader 副本根据收到的确认信息,更新高水位。
Epoch:
- Epoch 是一个单调递增的版本号,用于标识 Leader 副本的变更。
- 每当发生 Leader 选举时,新的 Leader 副本会生成一个新的 Epoch 值。
- 每个副本都会维护自己的 Epoch 值。
- 当 Leader 副本发生变更时,新的 Leader 副本会广播新的 Epoch 值。
作用:
- 防止数据不一致: 在 Leader 切换时,Epoch 可以防止旧的 Leader 副本上的“陈旧”数据被错误地当作“最新”数据。
- 确保数据安全性: 当一个分区发生 Leader 选举时,新的 Leader 会生成一个新的 Epoch 值,并将自己的 Offset 作为新的高水位。 这样,即使旧的 Leader 重新加入集群并尝试成为新的 Leader,由于其 Epoch 值较低,将无法通过高水位的校验,从而避免了数据不一致的问 1 题。
备忘
- 禁用自动提交位移,改为手动提交。只有当成功消费了消息才提交位移,防止消息丢失。
参考
https://towardsdev.com/kafka-101-a-beginners-guide-to-understanding-kafka-2cd797864614