hey 是一个用 Go 编写的 HTTP 压力测试工具,可以模拟大量并发请求。
1 | go install github.com/rakyll/hey@latest |
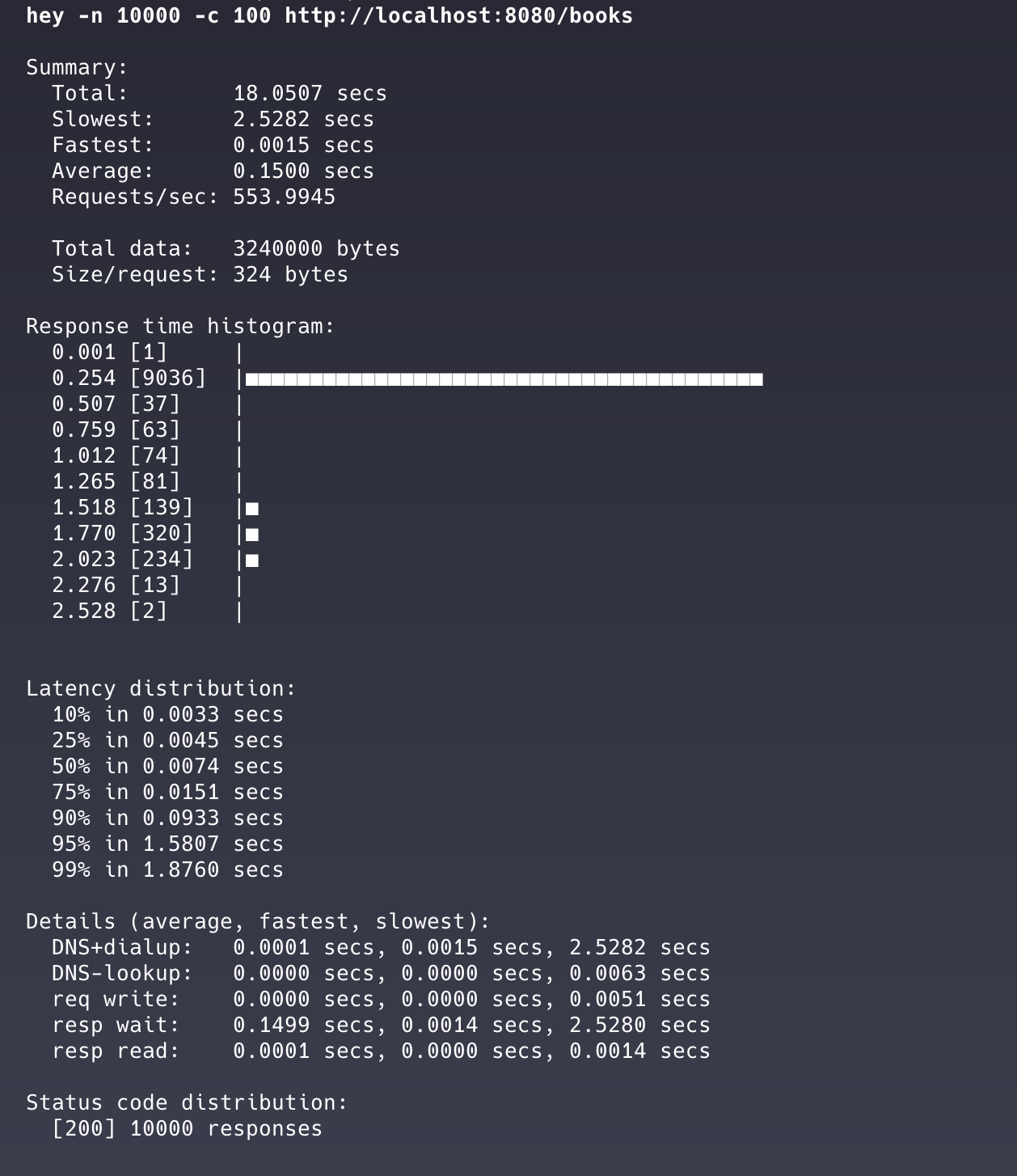
hey 是一个用 Go 编写的 HTTP 压力测试工具,可以模拟大量并发请求。
1 | go install github.com/rakyll/hey@latest |
在本地运行 go 应用程序的时候,默认情况下会导致系统防火墙弹窗
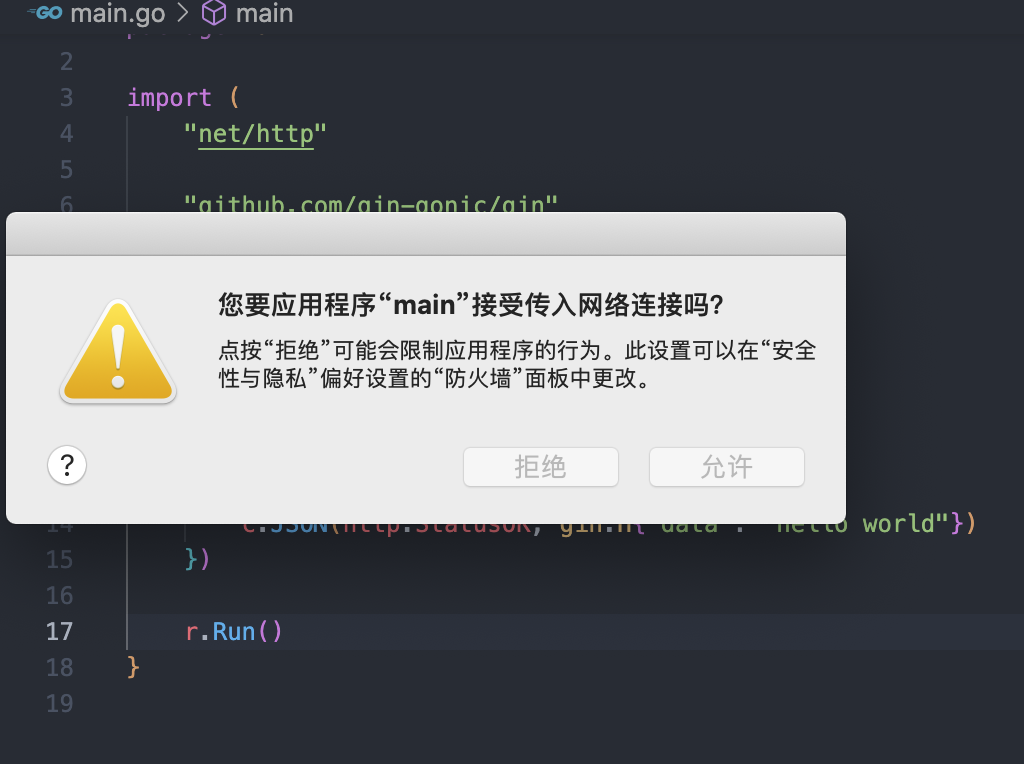
需要检查你的 Go 应用程序是否正在监听所有网络接口(例如使用 0.0.0.0 或::)。这可能会触发防火墙弹窗。建议改为监听本地回环地址 127.0.0.1,除非你的应用程序需要接受来自外部的连接。
我们的应用程序不需要接受来自外部的连接,所以只需要监听 127.0.0.1 就可以了
1 | package main |
在 Go 语言中,map 是引用类型,但在函数参数传递时,仍然是按值传递的。这意味着当你将一个 map 传递给函数时,传递的是 map 引用的副本,而不是原始的引用。因此,在函数内部对 map 引用本身的重新赋值不会影响到原始的 map。
解释
changeMapM 函数:
传递的是 map 引用的副本。
在函数内部,通过引用修改 map 中的值,这会影响到原始的 map,因为引用指向的是同一个底层数据结构。
changeMapN 函数:
传递的是 map 引用的副本。
在函数内部,重新赋值 n,这只是改变了 n 引用的副本指向一个新的 map,不会影响到原始的 map。
解释
changeMapM 函数:
m[“hello”] = 2:修改了 map 中的值,因为 m 引用指向的是原始的 map。
changeMapN 函数:
n = map[string]int{“hello”: 2}:重新赋值 n,使其指向一个新的 map,但这不会影响到原始的 map,因为 n 只是引用的副本。
总结
在 Go 语言中,map 是引用类型,但函数参数传递是按值传递的。
在函数内部对 map 引用本身的重新赋值不会影响到原始的 map。
要修改原始的 map,需要通过引用修改其内容,而不是重新赋值引用。
在 Go 语言中,map 的底层实现使用了桶(bucket)来存储键值对。当桶中的键值对数量超过一定限制时,会创建溢出桶(overflow bucket)。此外,当 map 中的键值对数量增加到一定程度时,map 会进行扩容,以保持较低的哈希冲突率和较高的性能。
创建溢出桶(overflow bucket)
溢出桶是在以下情况下创建的:
桶已满:每个桶有一个固定的容量(通常是 8 个键值对)。当一个桶中的键值对数量超过这个容量时,会创建一个溢出桶来存储额外的键值对。
哈希冲突:当多个键的哈希值映射到同一个桶时,会发生哈希冲突。如果桶已满且发生哈希冲突,会创建溢出桶来存储冲突的键值对。
扩容
map 会在以下情况下进行扩容:
负载因子超过阈值:负载因子是 map 中键值对的数量与桶的数量之比。当负载因子超过某个阈值(通常是 6.5)时,map 会进行扩容。扩容时,map 的桶数量会增加一倍,以减少哈希冲突并提高性能。
溢出桶过多:如果 map 中有太多的溢出桶,说明哈希冲突较多,map 也会进行扩容,以减少溢出桶的数量。
总结
溢出桶:当桶中的键值对数量超过容量或发生哈希冲突时,会创建溢出桶。
扩容:当负载因子超过阈值或溢出桶过多时,map 会进行扩容,以减少哈希冲突并提高性能。
这些机制确保了 map 在存储大量键值对时仍能保持较高的性能和较低的哈希冲突率。
If a map isn’t a reference variable, what is it?
there-is-no-pass-by-reference-in-go
https://dave.cheney.net/2015/12/07/are-go-maps-sensitive-to-data-races
计算机三大事: 计算,网络,存储。你要在这上面下狠功夫。
Don’t feel you aren’t smart enough
Successful software engineers are smart, but many have an insecurity that they aren’t smart enough.
https://github.com/jwasham/coding-interview-university/blob/main/translations/README-cn.md
https://roadmap.sh/backend?r=backend-beginner
https://gitstar-ranking.com/repositories
https://github.com/clowwindy/Awesome-Networking
https://github.com/kowsertusher/Book
https://csdiy.wiki/en/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/topdown/
https://friskfrysefrugt.github.io/awesome-networking/
https://www.practicalnetworking.net/series/packet-traveling/packet-traveling/
Software Engineering at Google
https://google.github.io/building-secure-and-reliable-systems/raw/toc.html
https://victoriametrics.com/blog/go-slice/index.html
https://pkg.go.dev/unsafe#SliceData
slice 在传递给函数的过程中,如果没有指定内存地址传递,则传递的是 slice 的一个副本,
如果你希望改变 slice 的值,最好传递内存地址。
1 | package main |
利用go build命令可以查看变量是否逃逸到heap上
1 | package main |
初始化 slice 的时候最好预估数据量大小来设置 capacity,来避免频繁的创建新数组和复制数据。
修改 slice 最好传递引用,因为对于 int, string, array, slice 这些数据类型都是 passed-by-value 的形式传递参数的。
In Go, everything is passed by value.
https://towardsdev.com/kafka-101-a-beginners-guide-to-understanding-kafka-2cd797864614
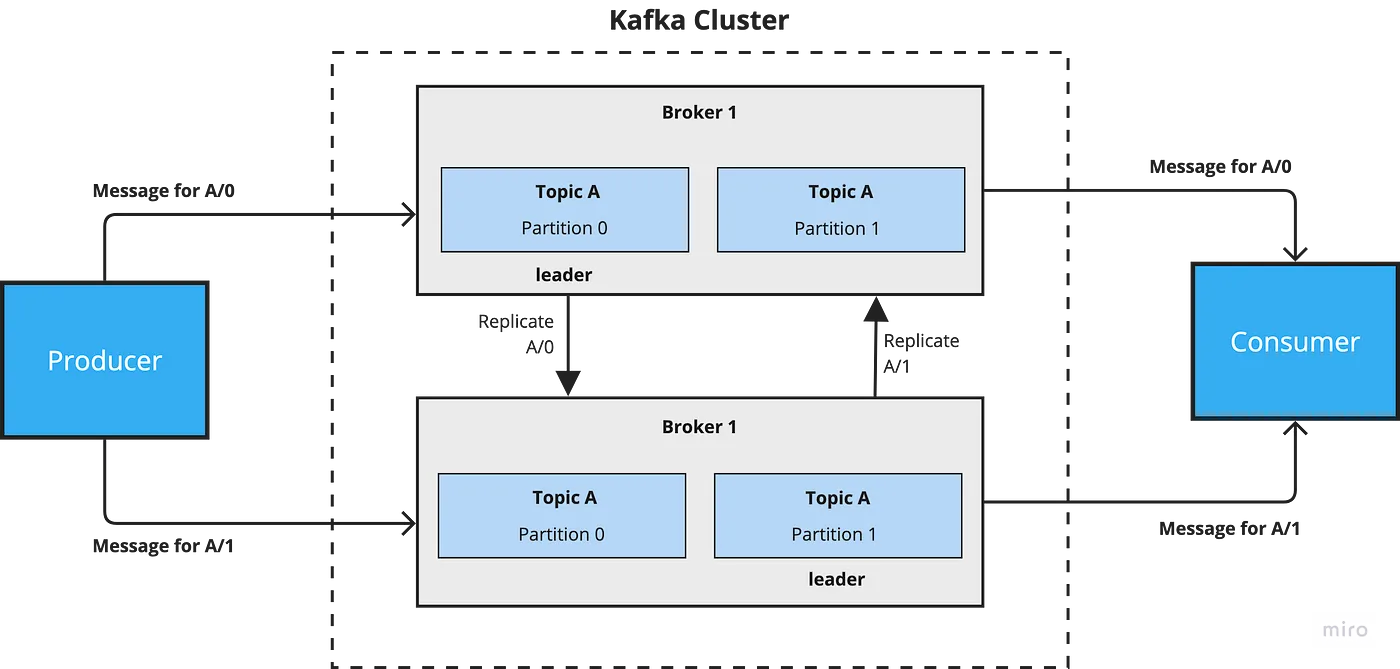
https://highscalability.com/untitled-2/
Kafka 集群中的分区(Partition)会不断地重新分配给不同的 Broker,以保证数据的高可用性和负载均衡。这个过程就叫做重平衡。
Kafka 的重平衡策略主要由 消费者组 (Consumer Group) 来控制。每个消费者组都有一个唯一的组 ID,组内的消费者共同消费一个或多个主题。
Kafka 的重平衡机制是保证集群高可用性和负载均衡的关键。通过了解重平衡的原理和影响因素,我们可以更好地优化 Kafka 集群的性能,并保证应用的稳定性。
如何避免重平衡
https://dzone.com/articles/kafka-streams-tips-on-how-to-decrease-rebalancing
https://dzone.com/articles/kafka-streams-tips-on-how-to-decrease-rebalancing
| 模板 | URL |
|---|---|
| vant4 | https://vant-ui.github.io/vant/#/zh-CN |
| Naive UI | https://www.naiveui.com/zh-CN/light |
| madewithvuejs | https://madewithvuejs.com/ui-components |
| element-plus | https://element-plus.org/zh-CN/ |
| nuxt templates | https://nuxt.com/templates |
| soybean-admin | https://github.com/soybeanjs/soybean-admin |
一致性 hash 算法主要应用在分布式系统中,试想 nginx 中配置的负载均衡策略是 hash,
即同一 IP 的请求都分发到同一台机器上,那么在添加一台或下线一台服务器后,假设你用的是
session 保存用户态的方式,你觉得它会出问题吗
实际上在 nginx 中也支持用一致性 hash 来避免这个问题
1 | upstream my_upstream { |
https://zh.wikipedia.org/wiki/%E4%B8%80%E8%87%B4%E5%93%88%E5%B8%8C